During my 25 years in the image processing software field, one algorithm has appeared over and over again. It has surfaced in obvious places, but also in projects and tasks where you wouldn’t have thought of in the first place.
If I would be asked the question…
What is the single most important algorithm in image processing?
… I certainly would have an easy answer.
I
t is an easy answer for me, because I have been using this algorithm in various fields, and the projects I have been using it in have been generally successful; sadly I cannot say this for all of the projects in my career.
What is this algorithm?
I’m thinking about correlation, sometimes also called normalized gray-scale correlation.
Wikipedia defines correlation as:
In statistics, correlation (often measured as a correlation coefficient, ρ) indicates the strength and direction of a linear relationship between two random variables…
In vision applications, the first variable is an image x under inspection and the second variable is some pattern y we want to identify. Mathematically, the correlation coefficient rxy can be calculated as follows:
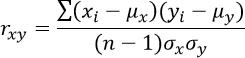
where µx and µy are the means and σx and σy are the standard deviations of x and y and n is the number of samples. This can be further transformed to

and
![]()
which may be nearer to coding this in a programming language.
Why is this algorithm so effective?
Computer vision is hard. It is much harder than you would anticipate at first glance. After all, if humans observe the world around, things look clear to us. We can identify traffic signs, read the text on them, we recognize in parts of a second, if some vehicle is moving or standing still, and so on. We do not have to make any conscious effort – all this feels naturally to us. Because this comes so easily to us, we tend to think that vision is easy. Usually, we do not recognize that there is an enormous computing machine in our head called brains, which is doing the heavy lifting.
You can get an idea of how hard vision is, when the conditions get bad. Imagine rainfall and fog at night, and you begin to understand. Gradually, reading the text on traffic signs gets more difficult and if the lighting conditions worsen reading may become impossible.
That is the state of vision as it is now: we have optics which are imperfect and act as low-passes, sensors and electronics which impose a lot of noise when converting light to electricity, and we have insufficient computing power to make sense of the generated image data. Current systems are literally driving in the dark, with heavy rains and fog reducing sight.
Conventional algorithms have a hard time recognizing and measuring objects, because the data is so noisy and convoluted. Image data is stochastic in nature, which is why some stochastic algorithms are needed to make sense out of the data. Correlation is one of those stochastic algorithms, which allows calculating the grade of matching between an image and a pattern.
An obvious use of correlation is pattern matching: you define a pattern or model, and you try to find it again at some location in subsequent images. The normalization makes this independent of changes in brightness, and due to the stochastic nature, noise introduced to the image pixels often cancels out nicely. This makes the method very robust.
A little less obvious is the use of correlation to detect edges in images. Classic edge detection often uses filters, or spline interpolation which tends to emphasize noise because of the differentiation that is employed. This makes the classic methods sensible to noise. However, you could also regard edge detection as matching the image with a synthetic model of an edge, and all of a sudden you gain the inherent advantages of correlation and end up with robust edge detection.
Still less obvious is the use of correlation for barcode decoding. Because barcodes are a commodity, they tend to be captured with cheap equipment, and thus tend to end up very small and in bad quality in the inspection images. Very good algorithms are needed for decoding, and classic edge based methods often fail, when the module size gets small enough. Much better recognition rates can be achieved with the use of correlation techniques.